Javier Tamayo-Leiva
About myself...
I am Javier Tamayo Leiva, I received my PhD in Genetics and Microbiology at the Pontificia Universidad Católica de Chile. Due to my great interest and curiosity for science and big data I did my PhD in Genetics and Microbiology with a focus on visualization, statistical analysis and data modeling, to study microbial processes of genetic dispersion in communities. I really enjoy approaching analyses with the goal of building and sharing knowledge and value from data. Therefore, I am always eager to learn new topics, techniques and ways to expose information through dynamic tools. Thus, throughout my career I have acquired advanced knowledge in R, WebScrapping, data engineering, report generation -R Markdown and Jupyter Notebook- and applications with R Shiny. I also have knowledge in HTML, CSS and HUGO. And I am currently focused on learning more about Python and SQL.
The reason for...
My undergraduate degree was in biotechnology, and my main focus was microbiology, so from then on, I understood the importance of what is out-of-sight. Therefore, if my interest was to understand these out-of-sight systems, it was necessary not only to generate reliable experimental designs for reliable data - the basis of any study - but also to work with large databases, because to understand real systems is not enough to study a controlled environment, you have to go out and see the real world! So, I put on my explorer’s suit and became an environmental microbiologist, which has been very entertaining and has allowed me to study diverse and wonderful environments such as the Patagonian Fjords and Antarctica. However, although all these experiences contributed to the scientific training that allowed me to face the first challenge, working with large databases and the necessary knowledge, such as programming languages and their logic and statistical modeling, were a whole new challenge for me.

The experience...
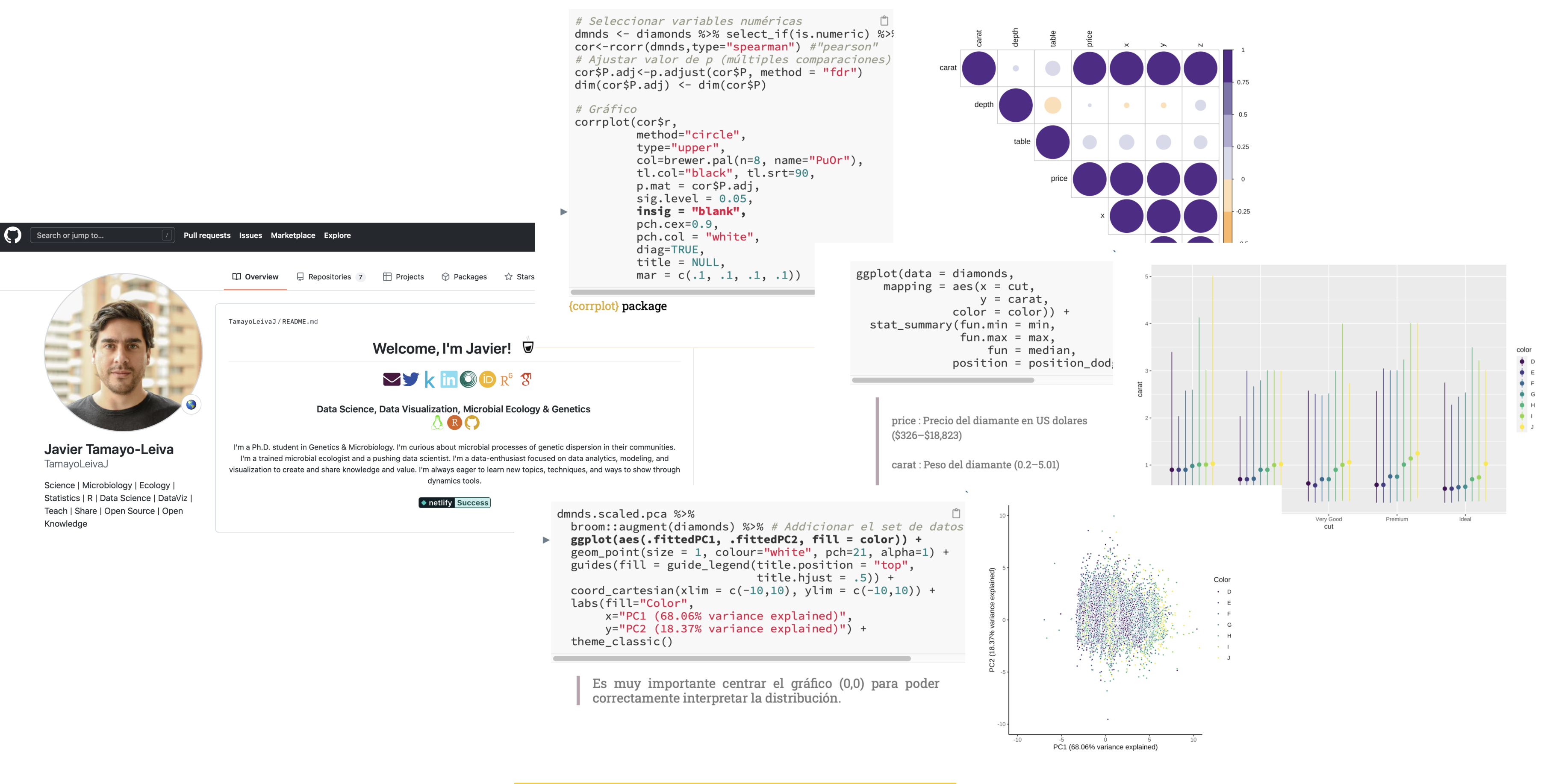
It was then throughout my doctorate that I began the process of learning to program from scratch, which, although it was a great challenge because, in college, I never had programming courses, allowed me to obtain tools to learn other things autonomously. Currently, I manage to program in Bash, R, and I am comfortable working with git and GitHub. I have advanced handling in visualization libraries such as {ggplot2}{ggfx}{ggimage}{plotly}, along with many other tools and libraries that allow me data wrangling and manipulation with libraries such as {janitor} and the {tidyverse} collection, together with the statistical processing of data in R, which being a lingua franca for statistics has a wide collection of packages oriented to these analyses. Additionally, as my focus from the beginning was to generate complete analyses from data to graphics, I have learned to make reports with {rmarkdown} and applications with {shiny} which has allowed me to increase my options when communicating with the information. Finally, I have also used R to generate web pages -like the one you are visiting- with {bloogdown} and HUGO, along with interactive presentations on {reveljs} and {xaringan}, which are most useful when it comes to sharing or teaching about code, all the reasons why I also had to learn HTML and CSS.
If you are looking for more information about my education and professional experience, here is my resumé.
Contact
Interested in learning more about my work, need advice on your analysis or want to learn something related to my experience? Let’s get in Contact! for quotes and/or joint projects.